
About Me
Hi! This is Zejun Li. I am currently a Ph.D. candidate at Fudan Univeristy, where I am fortunate to be advised by Prof. Zhongyu Wei. I am a member of the Fudan Data Intelligence and Social Computing (Fudan DISC) lab and the Fudan NLP group. Previously, I had the opportunity to visit the UCSB (University of California, Santa Barbara) NLP group, where I worked with Prof. William Wang.
My research focuses on multi-modal learning across vision and language, particularly:
- Construction and Evaluation of Large Multi-modal Models (LMMs)
- Exploring Visually-enhanced Reasoning abilities in LMMs
- Vision-Language Pre-training
📝 Publications
Zejun Li*, Yingxiu Zhao*, Jiwen Zhang, Siyuan Wang, Yang Yao, Runzhou Zhao, Jun Song, Bo Zheng, Zhongyu Wei.
[GitHub Project (Coming Soon)]
- We present Mixture-of-Visual-Thoughts, an adaptive reasoning paradigm that unifies different thinking modes within one model and guides it to select the appropriate one based on context.
- We introduce an adaptive learning framework, including an RL algorithm AdaGRPO, tailored for inducing context-adaptive mode selection capabilities.
- We construct AdaVaR-3B and AdaVaR-7B, which achieve consistent improvement across various scenarious!

VoCoT: Unleashing Visually-Grounded Multi-Step Reasoning in Large Multi-Modal Models
Zejun Li*, Ruipu Luo*, Jiwen Zhang, Minghui Qiu, Xuanjing Huang, Zhongyu Wei.
[GitHub Project] [Data] [Model]
- We present VoCoT, a multi-modal interleaved reasoning CoT format for MLLM.
- We construct a SFT dataset to enable LMMs to reason with VoCoT!
- We construct VolCano, a VoCoT-enhanced LMM, which is able to perform reasoning with visually-grounded and highly explainable thoughts!
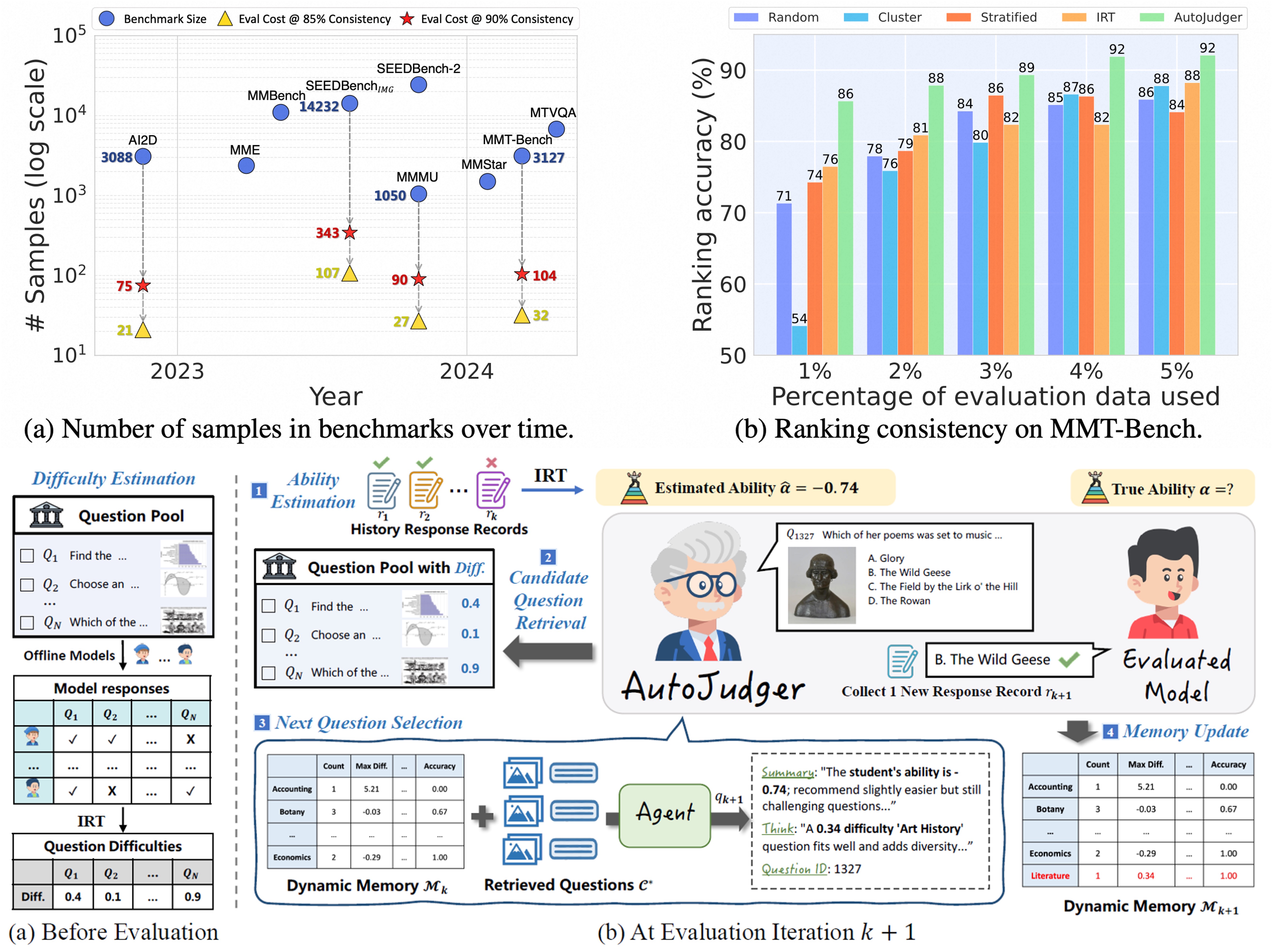
AutoJudger: An Agent-Driven Framework for Efficient Benchmarking of MLLMs
Xuanwen Ding*, Chengjun Pan*, Zejun Li*, Jiwen Zhang*, Siyuan Wang, Zhongyu Wei.
- We formulate the task of multi-modal efficient benchmarking: select representative subsets from benchmarks for efficient evaluation.
- We propose an agent-driven framework, AutoJudger, which leverages an interviewer agent to dynamically select suitable questions for the subject (the evaluated model).
- With AutoJudger, only 2%~5% data (<10% computational cost) leads to >90% consistency with full-scale evaluation for most benchmarks.
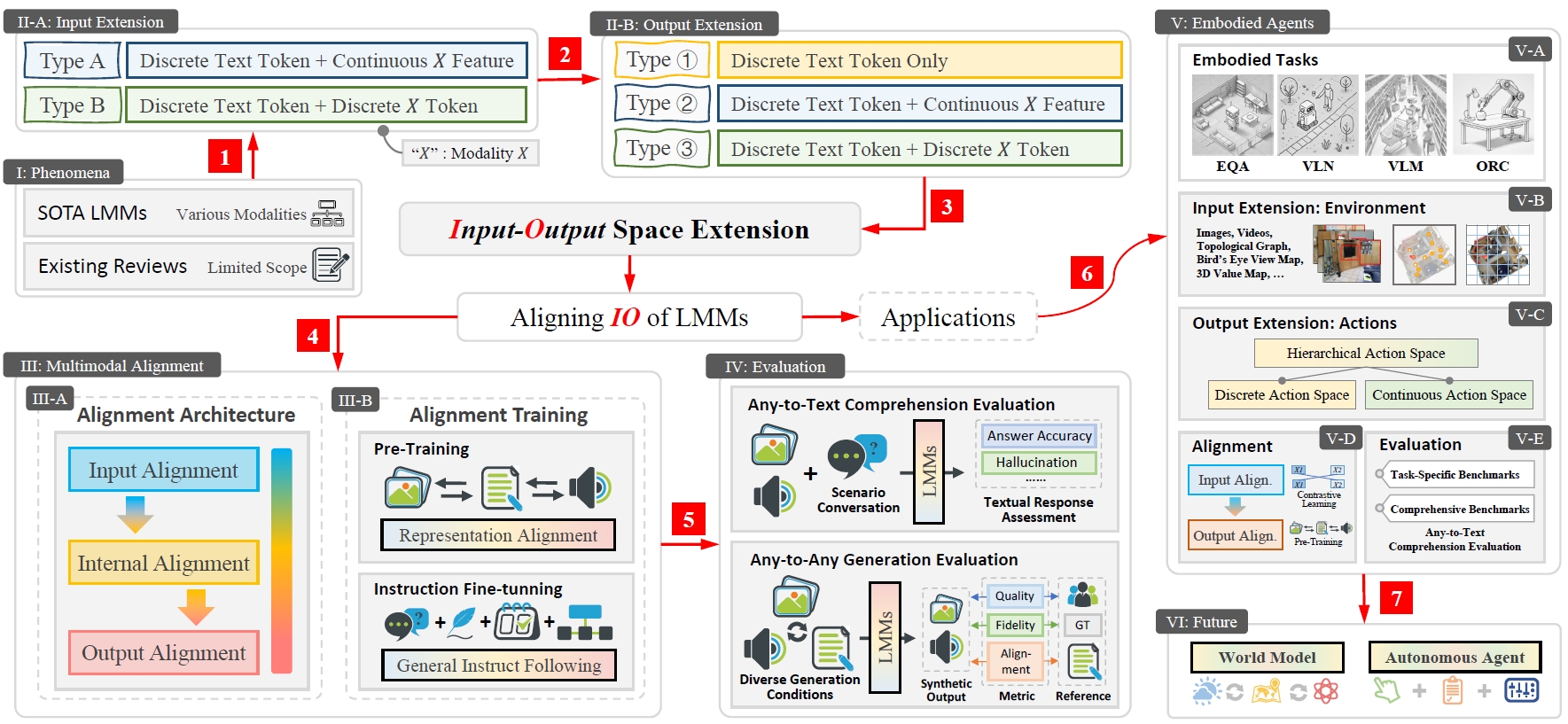
Zejun Li*, Jiwen Zhang*, Dianyi Wang*, Ye Wang*, Xuanjing Huang, Zhongyu Wei.
- We review and summarize existing LMMs from an unified and straightforward perspective: input-output space extension.
- We discuss various model architectures, training datasets, and evaluation stratigies, aiming to provide a comprehensive overview for readers.
- Our survey also talks about how to extend the input-output space to embodied environments, leaving rooms for future development.
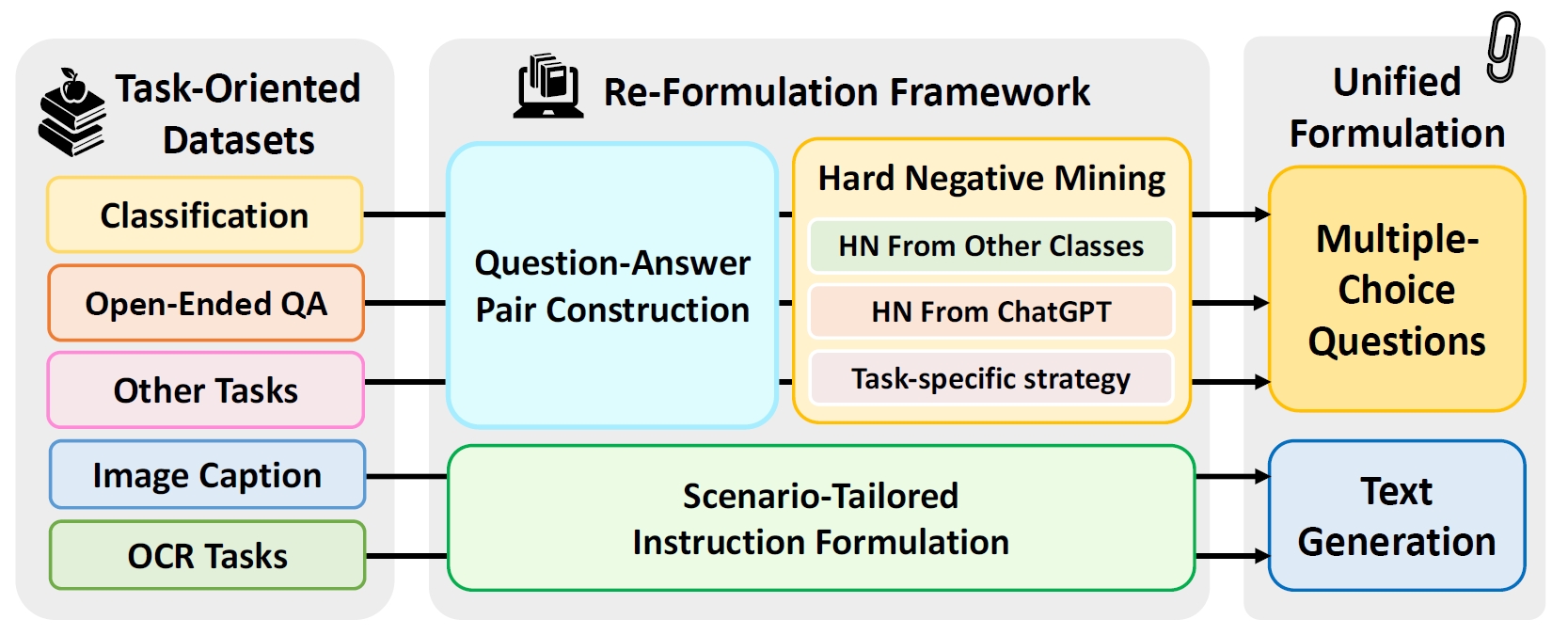
Zejun Li*, Ye Wang*, Mengfei Du*, Qingwen Liu*, Binhao Wu*, Jiwen Zhang*, et al.
- An effective method to transform task-oriented benchmarks to formats that are compatible to evaluate LMMs based on open-ended generation.
- Please also see EmbSpatial-Bench for a benchmark dedicated for the diagnosis of the main limitation of current LMMs, namely spatial reasoning.
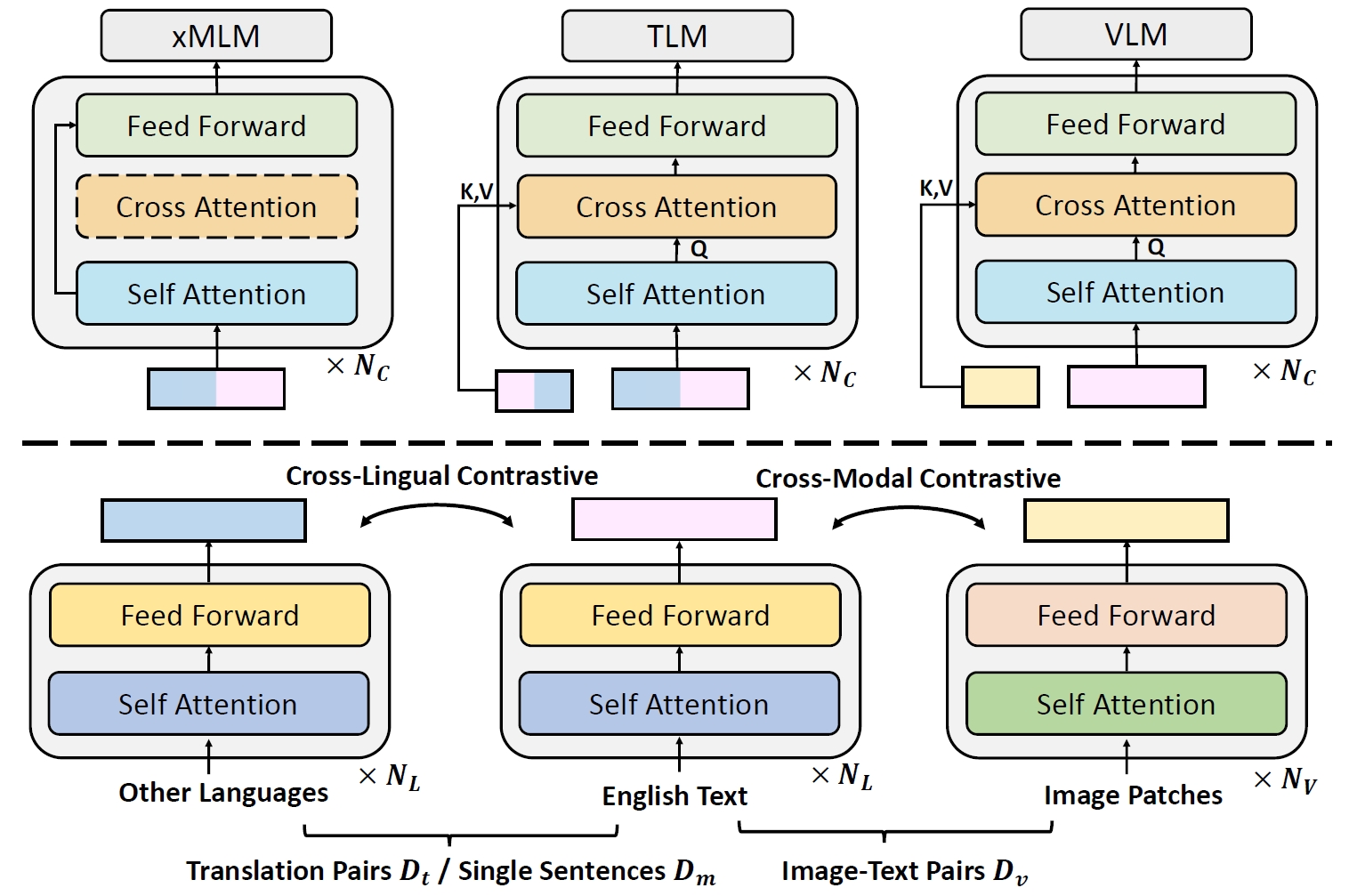
Zejun Li, Zhihao Fan, Jingjing Chen, Qi Zhang, Xuanjing Huang, Zhongyu Wei
- We propose a method to transfer English vision-language models to multilingual scenarios without the need for multilingual image-text data.
- Leveraging English text as anchors, our model is trained with English image-text pairs and English-to-others translation pairs.
- Multi-modal ability learned from English image-text data can be transfered across languages with our method.
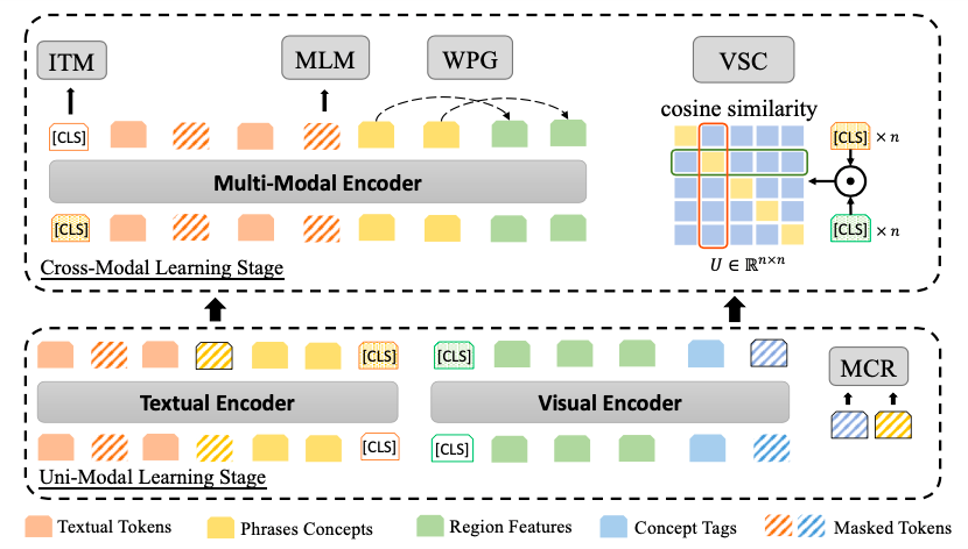
MVPTR: Multi-Level Semantic Alignment for Vision-Language Pre-Training via Multi-Stage Learning
Zejun Li, Huaixiao Tou, Jingjing Chen, Zhongyu Wei, Xuanjing Huang.
- MVPTR is a vision-language pre-trained model with the ability to jointly model multi-level semantic alignment.
- Integrated with multi-grained information and learning, MVPTR demonstrates superior performance on downstream tasks.
- An Unsupervised Sampling Approach for Image-Sentence Matching Using Document-Level Structural Information. Zejun Li, Zhongyu Wei, Zhihao Fan, Haijun Shan, Xuanjing Huang. AAAI 2021.
- Activating Distributed Visual Region within LLMs for Efficient and Effective Vision-Language Training and Inference. Siyuan Wang*, Dianyi Wang*, Chengxing Zhou*, Zejun Li, Zhihao Fan, Xuanjing Huang, Zhongyu Wei. ACL 2025
- Unifying Local and Global Knowledge: Empowering Large Language Models as Political Experts with Knowledge Graphs. Xinyi Mou, Zejun Li, Hanjia Lyu, Jiebo Luo, Zhongyu Wei. WWW 2024.
- EmbSpatial-Bench: Benchmarking Spatial Understanding for Embodied Tasks with Large Vision-Language Models. Mengfei Du*, Binhao Wu*, Zejun Li, Xuanjing Huang, Zhongyu Wei. ACL 2024.
- DELAN: Dual-Level Alignment for Vision-and-Language Navigation by Cross-Modal Contrastive Learning. Mengfei Du*, Binhao Wu*, Jiwen Zhang, Zhihao Fan, Zejun Li, Ruipu Luo, Xuanjing Huang, Zhongyu Wei. COLING 2024.
- Negative Sample is Negative in Its Own Way: Tailoring Negative Sentences for Image-Text Retrieval. Zhihao Fan, Zhongyu Wei, Zejun Li, Siyuan Wang, Xuanjing Huang, Jianqing Fan. NAACL 2022.
- Constructing phrase-level semantic labels to form multi-grained supervision for image-text retrieval. Zhihao Fan, Zhongyu Wei, Zejun Li, Siyuan Wang, Haijun Shan, Xuanjing Huang, Jianqing Fan. ICMR 2022.
- Tcic: Theme concepts learning cross language and vision for image captioning. Zhihao Fan, Zhongyu Wei, Siyuan Wang, Ruize Wang, Zejun Li, Haijun Shan, Xuanjing Huang. IJCAI 2021.
📖 Educations
- 2020.09 - 2026.06 (estimated), Ph.D. Candidate in Statistics (Statistical Machine Learning Direction), Fudan University, Shanghai, China.
- 2016.09 - 2020.06, Bachelor of Computer Science, Fudan University, Shanghai, China.
💬 Teaching and Service
Teaching Assistant
- Head TA for “Introduction to Artificial Intelligence”, Fudan University, Spring 2020, 2021, Fall 2022.
- Organizer for “NLP training camp of Fudan DISC”, Fudan University, Spring 2023.
Program Committee:
- Area Chair of Multi-Modality: EMNLP 2024, NAACL 2025.
- Reviewer: ACL, EMNLP, AAAI, IJCAI, CL, ACM MM, TKDD, NLPCC, CCL.
Invited Talks
- “Evolution of the Vision-Language Pre-traning Framework”, in CSSNLP 2022 Student Seminar.
- “How to Eficiently Conduct Team-based Research?”, in SMP 2023, Student Seminar.
- “Rethinking Research Direction Selection in Your Graduate Career”, in YSSNLP 2024, Student Seminar.
💻 Internships
- 2025.05 - Now, intern of T-Star Lab at Taobao & Tmall Group of Alibaba, Beijing, China.
- T-Star Lab is a premier internship program for top talent within the Taobao & Tmall Group.
- We explore a novel adaptive visual reasoning paradigm, Mixture-of-Visual-Thoughts.
- By unifying different reasoning modes within a single model and guiding it to adaptively select the appropriate mode based on the questions, our AdaVaR model achieves consistent improvement across various domains.
- 2021.09 - 2022.09, intern of CV algorithm engineer at ByteDance E-Commerce Group, Shanghai, China.
- We construct a vision-language pre-trained model to encode video representations for Douyin Shop.
- Our model is applied to perform video rating and recommendation, ultimately helping to improve content moderation, distribution efficiency, and recommendation click-through rates.
- The reasearch findings are summarized in our ACM MM 2022 paper.
- 2019.06 - 2019.09, intern of machine learning algorithm enginner at Alibaba Koubei Group, Hangzhou, China.
- We develop a algorithm dedicated for distributing coupons for users based on their history behaviors.
- By combining deep models with behavioral features, we learn representations of both users and coupons, improving the usage rate of coupons at the same cost.